Number recognition 1-10 - How to represent numbers up to ten
1-10 counting test
Being preschoolers, the first step in math is for kids to learn number recognition 1-10. When they obtain this knowledge, then they are already able to recognize all the math numerals that exists. Now, let's take for instance a number like 46.
A child at the beginning may not know how to pronounce 46, but, at least he is already versed with the existence of 4 and 6. It is very easy for kids to learn how to represent numbers up to ten.

IMPORTANT FACTS ABOUT NUMBER RECOGNITION UP TO 10 PRACTICE
With our very interesting object patterns for kids, they will count every group of objects then tell which of the groups represent the number in question. In fact, as parents grab this our interactive math game, they are in essence instilling a lasting love for math in your kids.
Considering our diverse exercises, we equally have a 1 -10 counting test. This test is given simply to measure kid's conceptual knowledge of the number sense concept.
Moreover, since counting is part of our real life experiences, it is important that kids should master it at a very young age, and as well have an intuitive understanding of numbers in general.
Example – which group shows 6?
Hey kids, no panics ok. Relax.
- It is very easy to tell which group shows 6. You just need to count every object in each group beginning from 1.
- Secondly, any group with the last counted number “6”, then that group is the correct answer.
When we count the first group, 1, 2, 3, 4, we find 4 objects. It's not the one.
As we begin counting from the second group; 1, 2, 3, 4, 5, 6, we realize that the last counted number is 6.
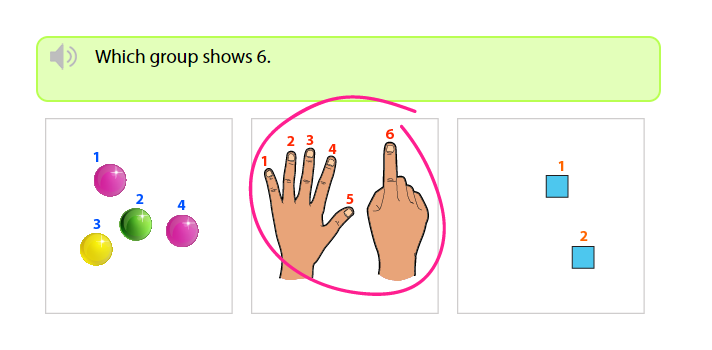
Definitely, the second group is the correct answer, because it shows 6.
- That's really quick, simple and awesome.
- I'll go for more of these same exercises.
Having clicked on the correct group, click on Next, to continue.